Die kindliche Neugier ist grenzenlos. Wann immer Kinder etwas nicht verstehen, wollen sie dieser spannenden neuen Sache auf den Grund gehen. Das führt immer zur Frage an die Eltern: Warum ist das so? Hat man eine einigermaßen kinngerechte Antwort gegeben, folgt sofort das nächste neugierige „Warum?“. Wieder versucht man eine abschließende Antwort zu geben, doch der Nachwuchs läßt sich nicht abspeisen – „Und warum?“.
Die kleinen Kinder gehen damit intuitiv wie bei einer Ursachenanalyse vor. Sie wollen eine Sache auf den Grund gehen. Sie sind auf der Suche nach der Ursache, der ultimativen Erklärung. Auf englisch nennen wir die „Root Cause“.
Unter einer Root Cause wird allgemein gesprochen ein Fehler in einer Software-Applikation oder einem digitalen Prozess verstanden. Genauer ist die Bezeichnung „Non-Konformität“, da das Verhalten nicht unbedingt einen Fehler im umgangssprachlichen Sinne darstellen muss. So könnte z.B. auch eine Hacker-Attacke auf ein System mit einer Root Cause Analyse untersucht und die ausgenutzte Schwachstelle (hoffentlich) gefunden werden.
Im abschließenden Schritt soll mit der RCA die Non-Konformität geschlossen werden. Die Root Cause löst die Ursachen-Wirkungskette aus, die schlußendlich zu einem oder mehreren Problemen führt.
Die Ursachenanalyse (Root Cause Analysis) beschreibt eine Menge an Vorgehensweise, Werkzeugen und Techniken, um zugrundeliegende Probleme einer Störung zu ermitteln.
Es finden sich Methoden der Ursachenanalyse, die die echten technischen Problemursachen zu identifizieren versuchen, während auch eher generelle Problemlösungstechniken genutzt werden können.
Woher kommt die Ursachenanalyse?
Die Ursachenanalyse gehört zum Bereich des Qualitätsmanagements und hier insbes. zur Methode des „Total Qualitäty Managements“ (TQM), die ihren Ursprung in der japanischen Automobilindustrie hat. Im TQM finden sich versch. Methoden und Techniken der Problemanalyse, Problemlösung und Ursachenanalyse (RCA).
Ursachenanalyse ist Teil eines übergreifenden Problemlösungsprozess und ist in der IT ein integraler Bestandteil des ITIL-Prozesses „Continual Service Improvement“.
Wie erfolgt eine (Fehler-) Ursachenanalyse?
Die wichtigsten Methoden finden sich im Folgenden:
Events and Causal Factor (ECF) Analysis: Die Methode ist verbreitet bei der Untersuchung von großen Einzelstörungen, wie z.B. eine Explosion in einer Raffinierie. Der Prozess nutzt die rasche und strukturierte Aufnahme von Beweise, die in die zeitliche Reihenfolge ihres Auftreten gebracht werden. Wenn die zeitliche Verlauf klar ist, werden die kausalen und unterstützenden Faktoren identifiziert.
Change Analysis: Diese Form der Ursachenanalyse wird genutzt, wenn sich die Performance eines Systems deutlich verschlechtert. Dabei werden alle Veränderungen bei Mitarbeitern, Ausrüstungen und Informationen untersucht sowie weitere Faktoren, die die Performance eines Systems beeinflusst haben könnten.
Fehlerbaumanalyse (Fault Tree Analysis FTA): Diese Methode eignet sich, um ausgehend von einem unerwünschten definierten Ereignis rückwärts gerichtet dessen Ursachen zu ermitteln, auch Top-down-Ansatz genannt. Man geht vom Allgemeinen zum Speziellen und prüft auf jeder Ebene des Systems eine mögliche Beteiligung der Subservices geprüft. Dabei entsteht eine baumartige Struktur der Fehlermöglichkeiten.
Kepner-Tregoe Methode (KT) und Entscheidungsfindung: Dieses Modell unterscheidet vier einzelne Phasen des Problemlösungsprozesses:
- Situationsanalyse
- Problemanalyse
- Lösungsanalyse
- Analyse potentieller Probleme
KT wird insbes. im Umfeld von Operational und Service Excellence angewendet. KT wird im Prozess „Problem Management“ von ITIL empfohlen.
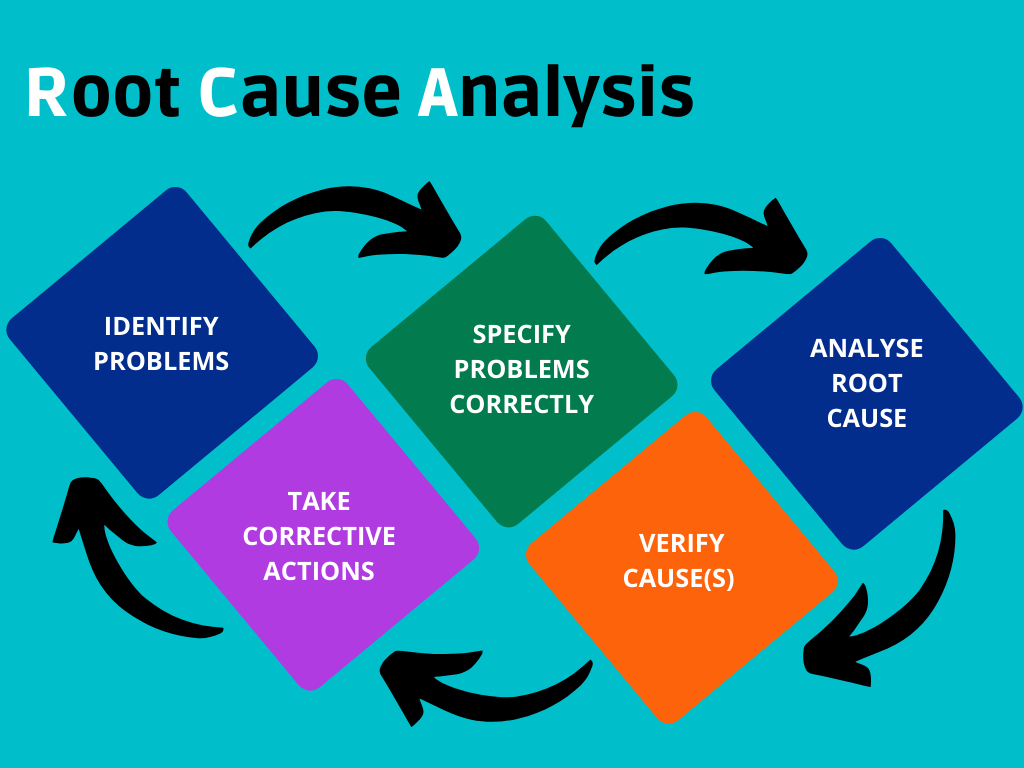
Durchführung einer Root Cause Analyse
Bei der Durchführung einer Ursachenanalyse sollten zwei grundlegende Rahmenbedingungen beachtet werden:
- Viele Methoden zur Ursachenanalyse können grundsätzlich von einer einzelnen Person angewendet werden, doch ist das Ergebnis in der Regel besser, wenn eine Gruppe von Personen gemeinsam an der Suche nach den Problemursachen arbeitet. Dabei können auch Kreativitätstechniken wie Brainstorming hilfreich sein. Dies gilt insbes. bei komplexen IT-Problemen.
- Diejenigen, die letztendlich für die Beseitigung der ermittelten Ursache(n) verantwortlich sind, sollten prominente Mitglieder des Analyseteams sein, das sich daran macht, sie aufzudecken.
Der ideal-typische Ablauf einer Ursachenanalyse ist wie folgt:
Es wird die Entscheidung getroffen, ein Team zusammenzustellen, das die Ursachenanalyse durchführen soll. Bei Organisationen, die nach den ITIL-Best Practices arbeiten, wird dies im Prozess „Problem Management“ abgearbeitet.
Die Team-Mitglieder werden aus dem Fachbereich ausgewählt, der das Problem berichtet. Ein verantwortlicher Manager sollte die Ursachenanalyse als Sponsor unterstützen, damit das Team auch die nötige Unterstützung durch andere Abteilungen und Bereiche erfährt. Es sollte weiterhin ein Kunde bzw. User dem Team angehören, der mit dem Problem im täglichen Arbeitsablauf zu tun hat.
Wie viel Zeit die Ursachenanalyse in Anspruch nimmt, hängt natürlich von der Komplexität des untersuchten Systems ab. Bei IT-Systemen wird nach einer größeren Störung meist erwartet, dass die Ursache innerhalb weniger Stunden oder Tage feststeht. Wird ein komplexer Produktionsablauf untersucht, kann die Analyse auch Wochen oder Monate dauern.
Dabei sollten während der Analyse alle Phasen gleich gewichtet werden:
- Definition des Problems
- Brainstorming möglicher Gründe
- Analyse von Ursache und Wirkung
- Ableitung einer dauerhaften Problemlösung
Während der Untersuchungen sollte das Team regelmäßige Meetings vereinbaren (mindestens wöchentlich, aber auch tägliche Meetings sind denkbar). Die Meetings sollten möglichst kurz gehalten werden (max. 2 Stunden) und sie sollten im Sinne der Problemfindung kreativ gestaltet werden, auf eine starre Agenda sollte verzichtet werden.
Ein Verantwortlicher (z.B. der Problem Manager) stellt sicher, dass die Ursachenforschung Fortschritte macht und das den Team-Mitglieder Aufgaben zugewiesen werden. Aufgaben und Beschlüsse sollten in einem Protokoll festgehalten und nach den Meetings an alle versendet werden.
Wenn eine Fehlerursache und eine Lösung dazu gefunden wurde, wird die Implementierung dieser Lösung geplant. Je nach erforderlichen Ressourcen und Skills kann die Implementierung der Lösung Tage, Wochen oder Monate in Anspruch nehmen.