Am Samstag, den 27. Mai 2017, kam es bei der britischen Fluggesellschaft British Airways zu einer schwerwiegenden technischen Störung, die als IT-Systemausfall in der Presse vermeldet wurde.
Was war passiert?
Betroffen waren Check-In, Website und Call Center der Airline. Weltweit waren Hunderte Flüge betroffen, es kam zu massiven Verspätungen und Flugausfällen. An den Flughäfen Heathrow und Gatwick kam es zu chaotischen Zuständen. Die Meldung auf ba.com las sich so:
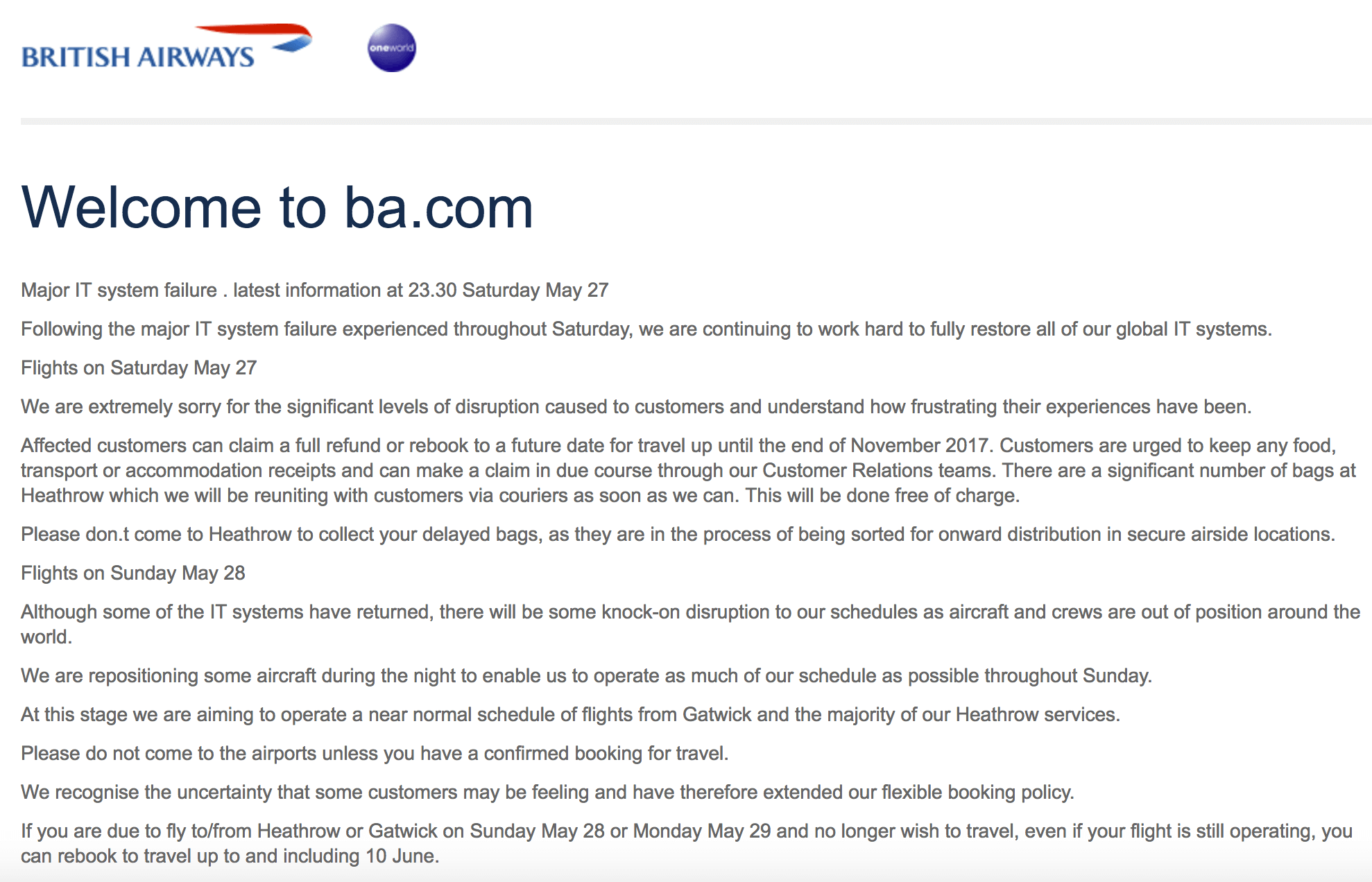
Mitteilung von British Airways zum IT-Systemausfall am 27. Mai 2017
Aus Kundensicht ist damit wohl der Super-GAU eingetreten. In Großbritannien war ein langes Wochenende und Tausende Urlauber wollten in den Urlaub fliegen. Die wirtschaftliche Dimension des Systemausfalls kann als dramatisch bezeichnet werden.
Die Frage ist nun, wo die Ursache des Problems lag. BA hat recht schnell einen Cyberangriff ausgeschlossen und auf einen Fehler in der Stromversorgung verwiesen. Doch kann ein Stromausfall in einem Rechenzentrum die IT-Systeme einer gesamten Airline mit einer Flottenstärke von mehr als 250 Flugzeugen lahmlegen? Hat sich etwa einen zweiten RZ-Standort gespart, der im Ernstfall den IT-Betrieb hätte übernehmen können? Experten für den Aufbau von Rechenzentren bezweifeln diese Theorie mittlerweile.
Oder war es doch ein Hackerangriff, vielleicht ein verspäteter Ausbruch der Ransomware Wannacry, die bereits Mitte Mai zu Chaos in vielen Firmen und beim britischen Gesundheitsservice NHS führte. Wir werden es wohl nie erfahren, Kunden, Mitarbeiter und Stackholder werden mit dem dürren Verweis auf ein Stromversorungsproblem abgespeist und der nächste Systemausfall lässt nicht lange auf sich warten. Dieser Vorfall war schließlich nicht der erste IT-Zwischenfall bei Britisch Airways. Bereits im September 2016 standen die Check-In-Systeme stundenlang nicht zur Verfügung, was zu chaotischen Zuständen an mehreren Flughäfen führte.
Welche Fehlerbilder sind wahrscheinlich?
Da auch andere Fluglinien wie z.B. Delta von ähnlichen Störungen betroffen sind, stellt sich die spannende Frage, welche Fehlerbilder überhaupt wahrscheinlich sind und wie sich deren Vermeidung erreichen lässt.
Die drei folgenden Kategorien drängen sich auf:
- Keine Redundanz, kein Backup, keine Resilienz der IT-Systeme bzw. des Rechenzentrums
Aus Kostengründen werden keine redundanten Systeme oder Rechenzentren vorgehalten. Backups von geschäftskritischen Datenbanken werden nicht angelegt bzw. ein Restore der Datenbank ist nie verprobt worden. Im Fall einer Airline ist dieses Fehlerbild sehr unwahrscheinlich, gesetzliche Vorgaben machen redundante Systeme zur Pflicht, ebenso sollten Krisenübungen der Standard sein. - Hackerangriff
IT-Systeme werden von Viren, Trojaner oder Ransomware befallen und funktional gestört. International organisierte Hackergruppen sind in der Lage, erheblichen Schaden anzurichten und Lösegeld zu fordern. Im Fall von BA ist dieses Szenario nicht unwahrscheinlich. Derartige Hackerattacken laufen oft von der Öffentlichkeit unbemerkt ab und vielleicht wurde sogar Lösegeld gezahlt, doch die Entschlüsselung der Dateien hat dann länger gedauert als gedacht. - Menschliches Versagen
Die Steuerung einer Airline durch IT-Systeme erfordert eine Vielzahl von spezialisierten Applikationen. Flugplanung und Crewplanung laufen oft in anderen Applikationen als die Reservierungs- und Buchungssysteme sowie die Check-In-Systeme. Wieder andere Applikationen sorgen für den Passierdatenaustausch zwischen den Abflug-Land und dem Zielland. Die USA verlangen über das System Vorab-Passagier-Informationssystem (APIS) die Daten aller Reisenden. Ohne die Vorab-Übertragung ist eine Einreise gar nicht möglich.
Weitere Applikationen sind Abrechnungssysteme, HR-Systeme für Einsatzplanung und Urlaubsplanung. Dieser „Application Stack“ ist oft historisch gewachsen und von unterschiedlichsten Dienstleistern programmiert. Der Gesamtüberblick zum Zusammenspiel der Systeme ist oftmals nicht (mehr) vorhanden. Outsourcing und Mitarbeiterfluktuation tun ihr Übriges, um das Applikations-Wirrwarr bablonische Ausmaße annehmen zu lassen. Werden an Systemen Änderungen vorgenommen, kann dies das komplexe Zusammenspiel der einzelnen Programme gefährden, im schlimmsten Fall kommt es zu einem Systemausfall.
Welchen Beitrag kann IT Service Management leisten?
Der Prozess BCM (Buiness Continuity Management) sorgt für eine konsequente Überprüfung der Betriebsfähigkeit einer Unternehmung. Dabei werden unterschiedliche Szenarien wie großflächige Stromausfälle, Brände, Naturkatastrophen, Flugzeugabstürze und Epidemien betrachtet und auf deren Eintrittswahrscheinlichkeit untersucht. Auf dieser Grundlage werden Strategien, Pläne und Handlungsanweisungen entwickelt, um diesen Schadenszenarien entgegen zu wirken.
Der entsprechende Prozess aus der ITIL-Welt heißt „IT Service Continuity Management“ (ITSCM). ITSCM ist mehr als ein DR-Konzept, der Prozess hat die kritischen Geschäftsabläufe im Blick und nicht nur mögliche IT-Disaster. ITSCM sieht Massnahmen für Wort-Case-Szenarien vor, also konkrete Handlungsanweisungen für den Fall der Fälle. Präventive Massnahmen wie funktionierende und geprüfte Backup-Mechanismen und Recovery-Optionen sind ebenfalls im Fokus von ITSCM.
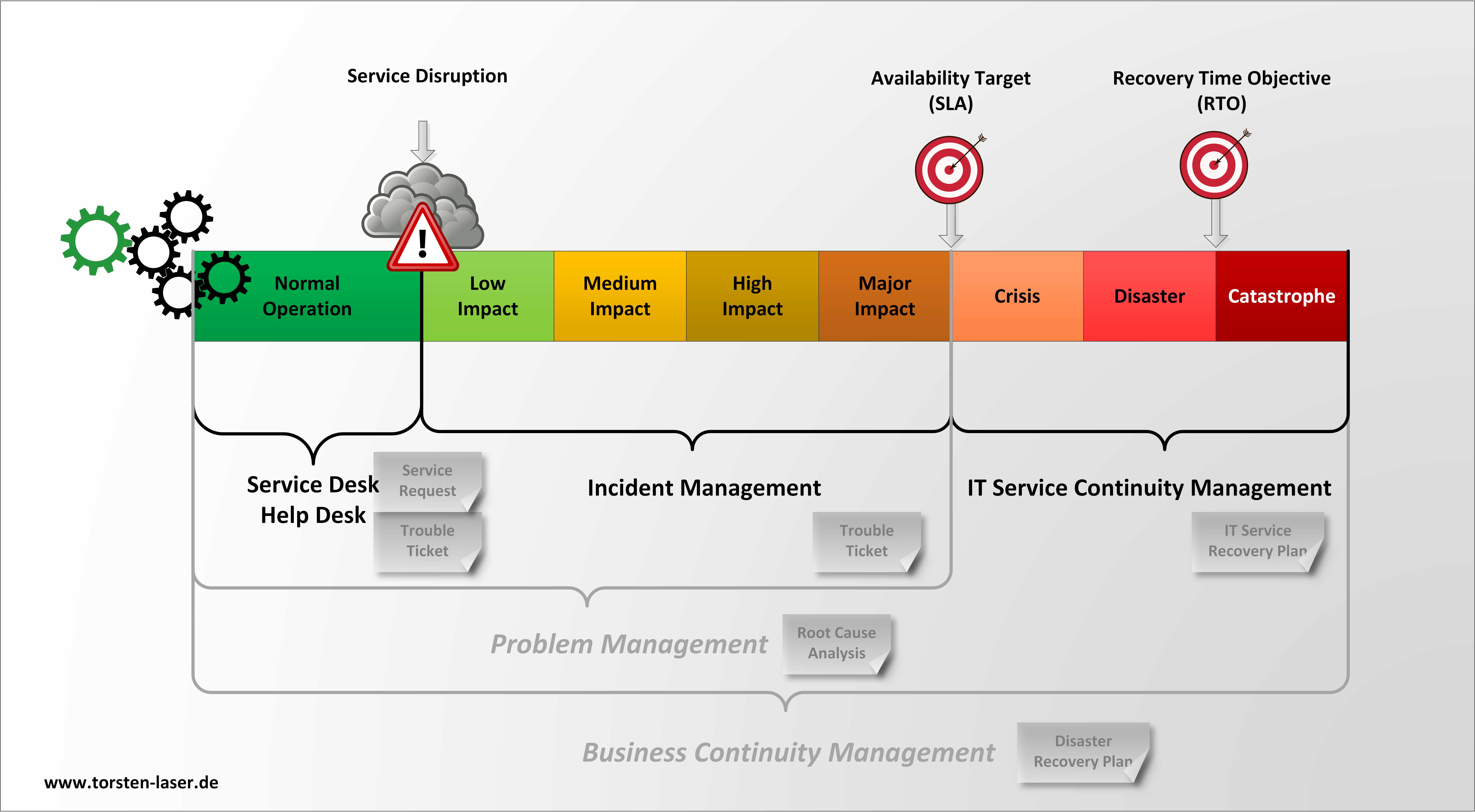
ITSCM Schematische Einordnung
ITSCM ist die technische Komponente des BCM. Moderne Unternehmen nutzen jedoch zunehmend komplexe IT-Services für ihren Geschäftsbetrieb, somit kommt dem ITSCM eine Schlüsselrolle in jedem Unternehmen zu, um großflächigen Systemausfällen vorzubeugen.

Schreibe einen Kommentar